Faiss解説シリーズ(第一回)基本編
最近、根詰めて触っているので詳しくなって来たついでに解説記事を書いてみた
Faissとは
Facebookが開発しているC++NNS(Nearest neighbor search)エンジン
- 手に入るライブラリの中では最高峰の速度
- 高次元ベクトルで問題になりがちなメモリー問題に対応できる機能群
- 億を超える数のベクトルを想定した多種のインデックスアルゴリズム
- これらを組み合わせる事で柔軟に用途にマッチしたトレードオフ戦略が取れる
簡単に言えば、どんなケースでも利用できる超柔軟なライブラリである。
NNSとANN(Approximate nearest neighbor)の超基礎
NNS
高次元のベクトルでは、あるベクトル群から、任意のベクトルに近いベクトルを抽出する場合には、総当りが第一選択肢だ。
低次元ならば、グリッドやハッシュなどの工夫によって効率良く抽出できる。高次元ではこれらの工夫は計算量的に裏目に出る。(次元の呪い)
ANN(Approximate nearest neighbor)
問題によっては抽出されるベクトルが厳密で無くとも良い場合がある。マッチ漏れや順位の上下などをある程度許容することで高速化を目指すアプローチだ。
Faissのインデックス
処理の流れ
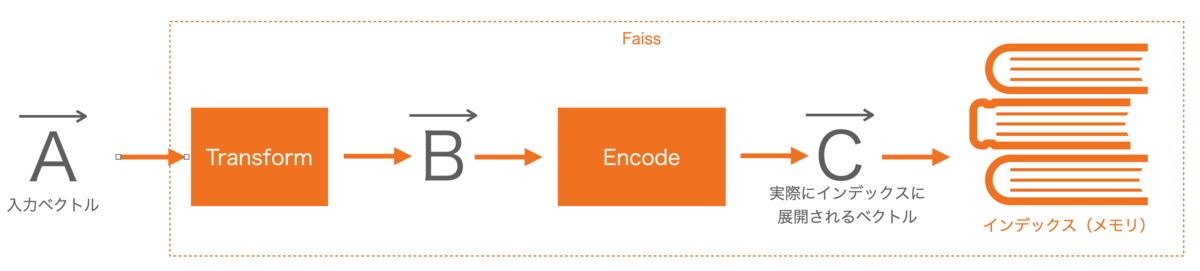
オレンジの部分がそれぞれ柔軟に差し替え可能。
ベクトルAが数万次元であっても(TransformやEncodeのトレードオフを受け入れる事で)ベクトルCを百次元未満にできれば、検索処理やメモリの負荷を大幅に削減できる。
またインデックス部分も単純にメモリ展開するだけだったり、グラフ構造や分散構造を選択できる。(もちろん各構造において色々なトレードオフがある)
Metric
ベクトルの距離計算の定義。主に以下の2つ
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| L2 | 平方ユークリッド距離 | 大小比較するだけならユークリッド距離と同意 |
| InnerProduct あるいは IP | 内積 | ベクトルを正規化しておけば(分母が1になるので)そのままコサイン類似度として使える。 |
基本インデックス
今回のメインコンテンツ。FlatとIVFだけ覚えるだけでも良い。
Flat
与えられたベクトルをメモリ空間にそのまま展開する。
検索は総当り。よって誤差は出ない。 それでもBLASに食わせ易く信じられないほど速い。
メモリーにそのまま展開するためベクトルのメモリー内順序で処理しID管理はしない(できない)。 利用側がベクトルを追加した順番を覚えておかなければならないので取り回しが悪い。
スクリプトなどで一時的なインデックスという使い方に良い。
IVF
総当りに耐えられない数のベクトルを、クラスタリングして小さな nlist 個のインデックスに分けておく。
検索時は、指定したベクトルに近いクラスタ(インデックス)を nprobe 個を対象に検索する。
クラスタリングの常として検索対象に入らなかったクラスタに、本当は近かったベクトルが入っている場合もあり、それらは検索結果から漏れる。
個人的には大体これを使う。
HNSW
ほぼグラフDBと同じ構造。
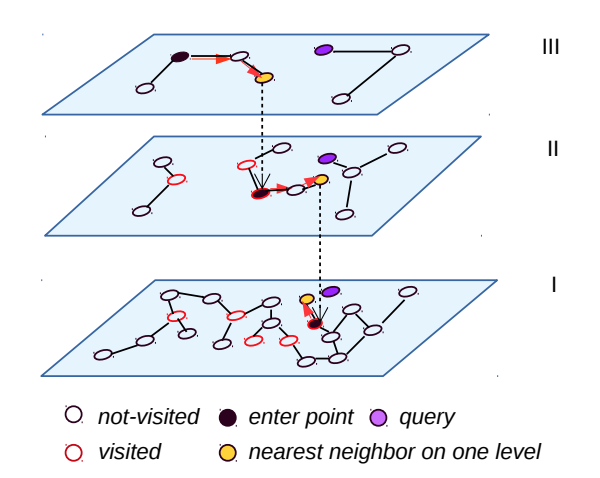
検索時にグラフが追えなくなってしまう為、一度入れたデータの削除ができない。
LSH
閾値の上下の2値化によるハッシュ
あまり精度を必要とせず、大まかな比較になる事が多い。
速度とメモリの制限が非常に厳しい場合の選択肢。
主なTransform
主に次元圧縮え使う事が多い。
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| PCA | 主成分分析 | 意味が薄い次元を省略し次元圧縮 |
| OPQ | ベクトル回転 | 後述のPQの効率化用 |
| RR | ランダム回転 | どう使うのか良くわからない |
| L2norm | 正規化 | ベクトルの大きさを1にする。MetricにInnerProductを指定すればcos類似度となる(実際の値は1-cos類似度)が予め入力ベクトルを正規化しておいた方が良い |
| ITQ | 勉強中 | 後述のLSHと一緒に使う |
| Pad | パディング | どう使うのか良くわからない |
主なEncoding
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| PQ | 直積量子化 | 解りやすい解説 |
| SQ | Scalar quantizer encoding | ちょっと良く分からない。単純なベクトル量子化の事だろうか? |
| RQ | 回帰分析の残差 | 回帰分析に上手く乗るデータ(トレーニングデータで実データを説明できるか?)では残差を量子化すると効率が良い |
| LSH | しきい値以上か未満の2値に量子化 | 高次元ベクトルで次元圧縮をしたくない場合の選択肢 |
PQを使ってれば間違いないがちょっと考える事が多いので後日別途解説する予定。
Prefixes
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| IDMap | Flatインデックス専用 | メモリー上での実装のみでマップ情報込みでインデックスを永続化できない |
永続化出来ないのでプロセスが起動している間でしか使わないインデックスで採用する事になるが、そういうケースのデータ投入でID管理出来ないような順不同並列投入する事もあまり考えられない為、採用しにくい。
私見だが使い物にならない。
Suffixes
TransformやEncodeを経たデータの距離には誤差がある。 検索結果を返す前に生ベクトルで距離計算をやり直してソートする機能。
生ベクトルを保持する必要があるためメモリー負荷が大きい。
以下の2つがある。
- RFlat
- Refine
サンプルコード
速度が重要な問題なので、サンプルコードも高速な言語であるGOを採用。
Flat L2
最もシンプルなFlatインデックスで平方ユークリッド距離計算。
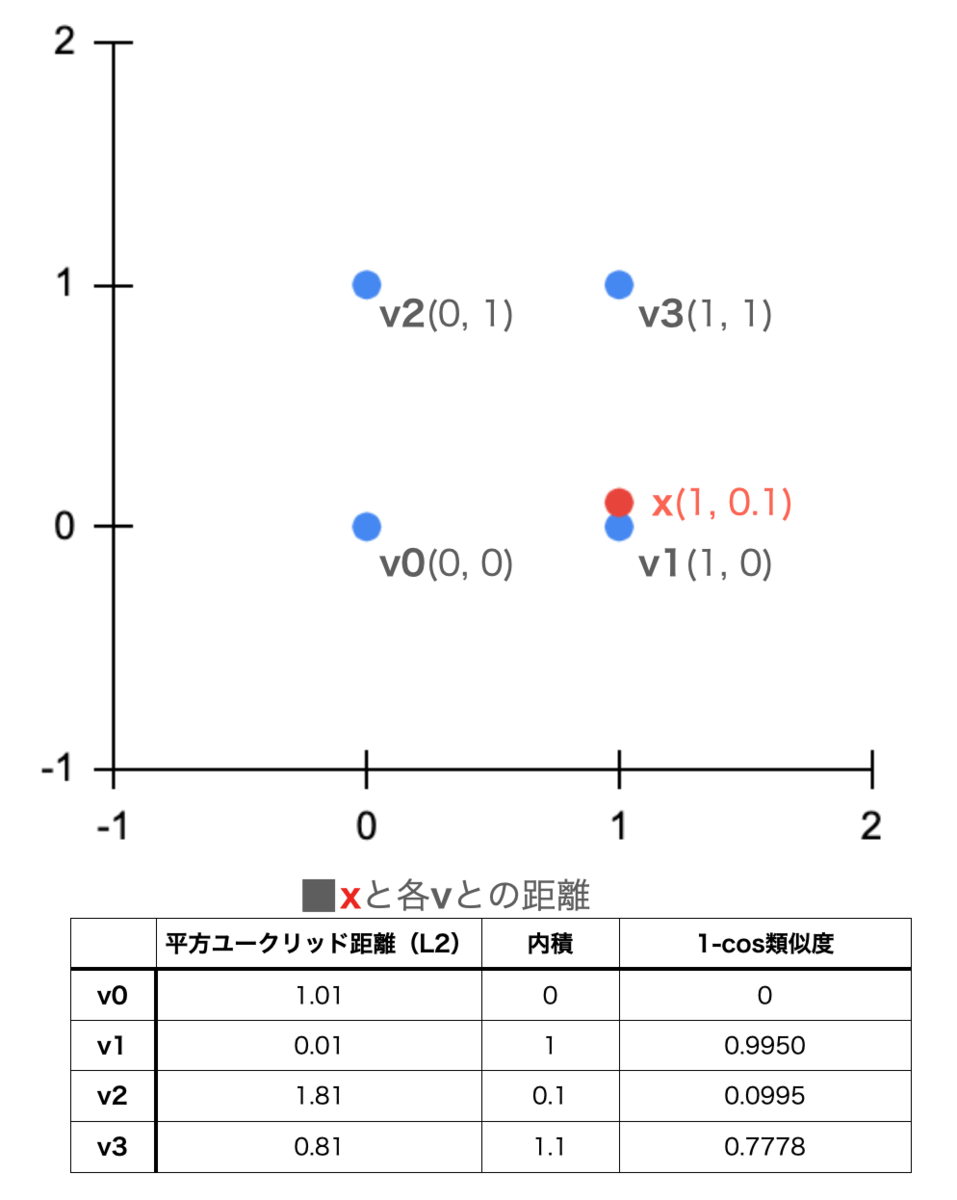
func Sample1() { fmt.Println("*** Sample1 Flat L2") index, _ := faiss.IndexFactory(2, "Flat", faiss.MetricL2) index.Add([]float32{0,0,1,0,0,1,1,1}) fmt.Printf("Ntotal: %v\n", index.Ntotal()) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
2 次元、 Flat 、L2 を指定したインデックスを作成
index, _ := faiss.IndexFactory(2, "Flat", faiss.MetricL2)
2 次元のベクトルを 4 個同時に投入。前述の通りメモリ展開順にラベルが 0, 1, 2, 3 と振られる。
index.Add([]float32{0,0,1,0,0,1,1,1})
実行結果
*** Sample1 Flat L2 Ntotal: 4 Distances: [0.010000001 0.80999994 1.01 1.81], Labels: [1 3 0 2]
Flat IP
メトリックに内積を指定
func Sample2() { fmt.Println("*** Sample2 Flat IP") index, _ := faiss.IndexFactory(2, "Flat", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** Sample2 Flat IP Distances: [1.1 1 0.1 0], Labels: [3 1 2 0]
Transform(L2norm)
正規化ベクトルの内積=1-cos類似度 (1に近い程、近距離と見なされる)
func Sample3() { fmt.Println("*** Sample3 L2norm Flat IP") index, _ := faiss.IndexFactory(2, "L2norm, Flat", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** Sample3 L2norm Flat IP Distances: [0.99503714 0.77395725 0.09950372 0], Labels: [1 3 2 0]
Suffix RFlat
TransformやEncodeとRFlatの組み合わせは上手く動かない。
Transform(L2norm) と RFlatを同時に使うと、RFlatの際にTransformが無視されて、単なる内積が帰ってしまう。
func RFlatDontWorkWithTransform() { fmt.Println("*** RFlatDontWorkWithTransform") index, _ := faiss.IndexFactory(2, "L2norm,Flat,RFlat", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) // RFlat returns simple IP, (Ignoring transform layer) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** RFlatDontWorkWithTransform Distances: [1.1 1 0.1 0], Labels: [3 1 2 0]
Suffix Refine
RFlatの代わりにRefineを使ってインデックスと同じ定義をしてあげれば良い。
func Refine() { fmt.Println("*** Refine") index, _ := faiss.IndexFactory(2, "L2norm,Flat,Refine(L2norm,Flat)", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** Refine Distances: [0.99503714 0.77395725 0.09950372 0], Labels: [1 3 2 0]
続き
全然書ききれないので、第2回も準備中。サンプルや検証を中心にしようと思っている。