AWSでもsysctlやらなきゃならんのか・・・
問題
構成
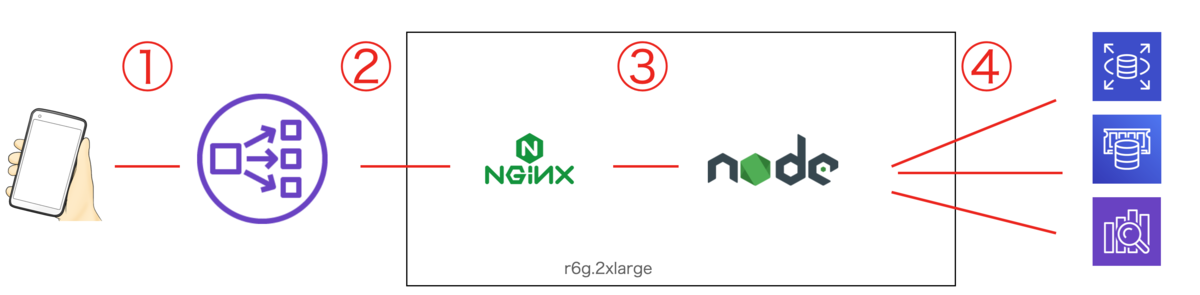
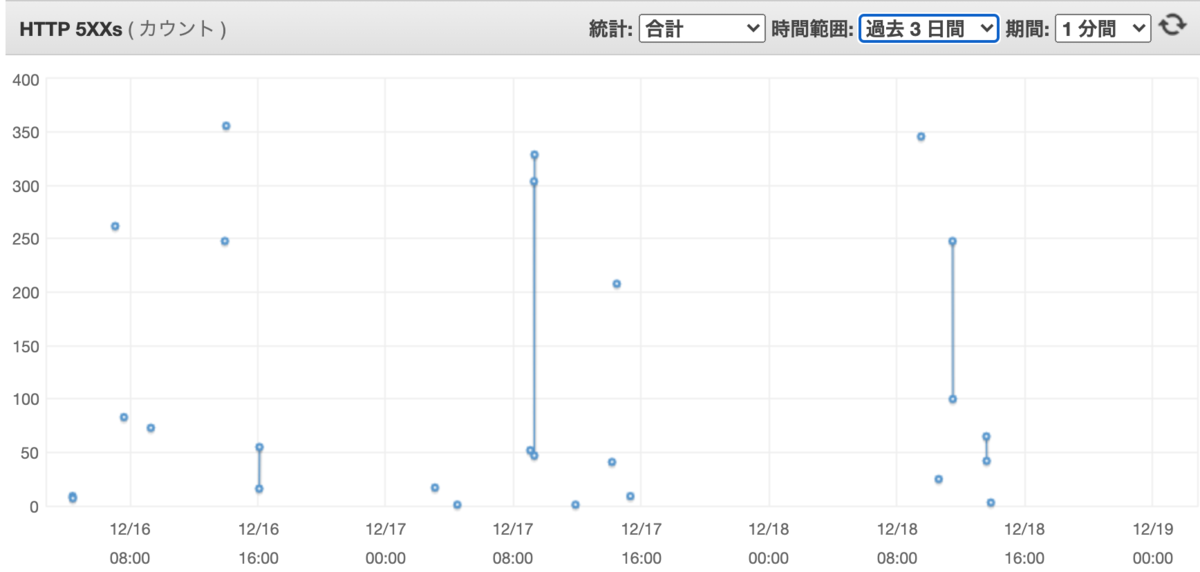
突発的に、1台のサーバーで5秒間だけ、502 Bad Gateway が数百〜数千出て困った。(②の部分)
- nginx.conf
proxy_connect_timeout 5;
5秒はnginx設定によるモノなのだろうが、なんで一瞬だけ出るのか全然解らなかった。
nginxのerror.log にはこう出てて、これってproxy_passの設定ミスってる時の奴だよな。。と。。(③の部分)
- /var/log/nginx/error.log
upstream prematurely closed connection while reading response header from upstream, client: 172.XX.XX.XX, server: _, request: "GET / HTTP/1.1", upstream: ...
一瞬、nginx -> node 間の unix socket の接続が詰まってパイプ詰まり問題でクライアント側まで詰まったのだろう。
パイプ詰まりにはバッファリングが常套手段なんだが、
しかしそもそもCPUもメモリーも問題無いのに、なんで詰まるんだ??
色々調べる内に全然違う部分の問題を発見する
$ netstat -s | grep -e 'pruned' -e 'collapsed'
1919109 packets pruned from receive queue because of socket buffer overrun
15131248 packets collapsed in receive queue due to low socket buffer
なんか多くないか?これ多少は出るのは良いんだが秒単位でガンガン増えてくのはおかしい。
EC2は色々なサイズのサーバーをスグに作れるし、気軽にサイズを変えられるし、そうするとCPU,メモリーどころかネットワーク帯域まで丸ごと変わるので細かいチューンをする気は無かった。
だけど、これ明らかにソケットバッファが足りてない!
これを踏まえて仮説を立てる
④の通信が滞って最終的には詰まり、瞬間的に③が何かしらの一時的リソース不足(※1)で受け付けられなくなり、②、①の502に至る。 だから④の通信をチューンすれば解決するのでは?
- ※1これも少なくとも5秒以内に解消する一瞬の問題なので捕まえられずにいる。計算上nfileやmaxconnでは無い事は解っている。heapsizeとかはあり得る。socketの先のカーネルで秒単位で起きる事といえば、ネットワークの輻輳が何かしらのロックを引き起こしている。とか。。しかしこれは追う気が起きない。多分追っても問題解消しねーし。
検証
えー今の時代にこんな細かい所調整すんのかよ・・・
net.core.somaxconn = 30000 net.core.netdev_max_backlog = 30000 net.ipv4.tcp_tw_reuse = 1
今までのsysctlの設定まさに動けば良い!的wこれが今風だと思っていた・・・
他はデフォを使っていて、特に関係ありそうな所はこの辺り。
net.core.rmem_default = 212992 net.core.rmem_max = 212992 net.core.wmem_default = 212992 net.core.wmem_max = 212992 net.ipv4.tcp_rmem = 4096 131072 6291456 net.ipv4.tcp_wmem = 4096 16384 4194304
ん?TCPのバッファってcore超えてて良いんだっけ?
調べたらMAX側が削られるだけらしい。
それでも200KBって少ない感覚だが昔の感覚と今の光配線やスイッチ性能だとレイテンシが段違いなんだろうな。
まずはネットワークバンドを確認
r6g.2xlargeは最大10Gbps だがPear To Pear だとどうなのよ?
# iperf Command 'iperf' not found, but can be installed with: apt install iperf
あ、、最近こんなことしないから入ってもいねーや
# apt install iperf
で、RDSやelasticCacheへは直接計測出来ないから、隣の別AZサーバー(placement groupではない)へ向けて計測
10K 位がメインの通信サイズ
ServerA
# iperf -s -w 1M
ServerB
# iperf -w 10K -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 20.0 KByte (WARNING: requested 10.0 KByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.1 sec 37.4 MBytes 31.1 Mbits/sec
案外細っ!、いやAZ超えればこんなもんか。やっぱ実測は大事。 1window 辺り3.2ms
1M 位が最大レベルの通信サイズ
ServerB
# iperf -w 1M -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 2.00 MByte (WARNING: requested 1.00 MByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 766 MBytes 643 Mbits/sec
1window辺り15ms
Round Trip Time (RTT)
# ip tcp_metrics : XXX.XXX.XXX.XXX age 2306.848sec cwnd 10 rtt 14817us rttvar 14478us source XXX.XXX.XXX.XXX :
redisへの計測値 elasticCacheと隣のEC2の経路は違うから、まあ参考値でしか無いが、redisとはかなり大きめのデータをやり取りしているようだ。
アプリとしては小さなキーを扱っているのだが、multiで纏めて送っているケースも多いのでまあ納得。
そしてこれは計算しなくても感覚的にやばい。
計算
TCPは再送があるので、向うにデータが到着して届いたよ。の返事が来るまで送信データを捨てられない。 elasticCacheはバンドの実測が出来ないので仮に1M windowの時のbpsを使う。
643 Mbits/sec * 14.817ms = 9527331 bits = 1190916 bytes
約1MBのバッファが必要なようだ。色々仮置数字がある計算なので、僕はこういう時は3倍にする。(感覚以外の裏付け無し)
設定を変えてもう一回計測
# sysctl -w net.core.rmem_max=3145728 # sysctl -w net.core.wmem_max=3145728 # iperf -w 1M -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 2.00 MByte (WARNING: requested 1.00 MByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 3.72 GBytes 3.19 Gbits/sec
おお!全然違うじゃねーか!! ちなみに10Kの方は 31.1 => 201 Mbits/sec
こうなると50MB近くバッファが必要になるな。でもこういう時には大体効かないもんだ。しかしやってみる
# sysctl -w net.core.rmem_max=52428800 # sysctl -w net.core.wmem_max=52428800 # iperf -w 1M -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 2.00 MByte (WARNING: requested 1.00 MByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 3.78 GBytes 3.24 Gbits/sec
うん。3Mでいい。
設定
そもそも
EC2はサーバサイズをフレキシブルに変えられるのも大きなメリットで、一緒に変わるネットワークバンドに合わせたチューンに依存したシステムは事故の元。本当は、ソケットバッファサイズは弄りたくない。
問題点の最終検証も兼ねてソケットバッファ以外の悪あがきをしてみる。
fin_timeout やコネクション数を弄って、枯渇リスクを回避できるか?
net.ipv4.tcp_fin_timeout = 5 net.ipv4.tcp_max_syn_backlog = 4096 net.core.netdev_max_backlog = 60000 net.core.somaxconn = 60000 net.ipv4.tcp_tw_reuse = 1
この辺の悪あがきも効かず。
net.ipv4.conf.default.accept_source_route = 0 net.ipv4.tcp_rfc1337 = 1
socket buffer をチューン
net.core.rmem_max=3145728 net.core.wmem_max=3145728
効いた!!
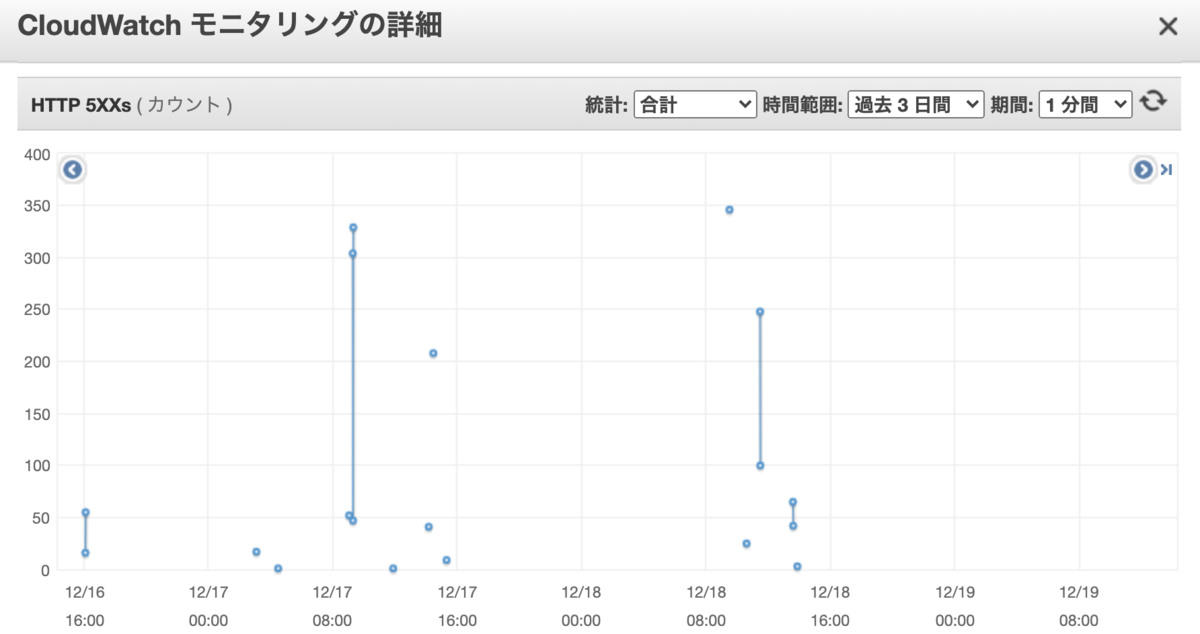
1日平和だった。ビックリするくらい劇的に改善!!
やっぱAWSパワーで解決はだめだ。順を追って丁寧に解決していくインフラ的な作業はまだまだ残るのだな・・・
おっさんの悩み
インフラ知識は本来コンピューターの全ての基本なのだが、これだけ発達した技術の中では全部身につけるのは非効率だと思う。 若い技術者は即効性のあるサービスに直結する新技術を学んで、すぐに戦力として活躍して欲しいし、殆どの人はそうしている。
それが効率的だ。
しかしそうすると誰もインフラが解らないチームが出来上がる。 一つ一つ細かく紐解いていく事が出来ない(思いも寄らない)から金で解決する事になる。でもこれって技術力の敗北だよね?
技術者全体、業界全体として力が失われていく圧力に他ならない。(今のSI界隈を見てると強く感じる)
また民芸の後継者問題よろしく、インフラ解る人が劇的に減ってきて、歯止めが掛かる気配がない。 やっぱり若い技術者もしっかりインフラをやらせた方が良いんだろうか?ぐるぐる。。。