Faiss解説シリーズ(第一回)基本編
最近、根詰めて触っているので詳しくなって来たついでに解説記事を書いてみた
Faissとは
Facebookが開発しているC++NNS(Nearest neighbor search)エンジン
- 手に入るライブラリの中では最高峰の速度
- 高次元ベクトルで問題になりがちなメモリー問題に対応できる機能群
- 億を超える数のベクトルを想定した多種のインデックスアルゴリズム
- これらを組み合わせる事で柔軟に用途にマッチしたトレードオフ戦略が取れる
簡単に言えば、どんなケースでも利用できる超柔軟なライブラリである。
NNSとANN(Approximate nearest neighbor)の超基礎
NNS
高次元のベクトルでは、あるベクトル群から、任意のベクトルに近いベクトルを抽出する場合には、総当りが第一選択肢だ。
低次元ならば、グリッドやハッシュなどの工夫によって効率良く抽出できる。高次元ではこれらの工夫は計算量的に裏目に出る。(次元の呪い)
ANN(Approximate nearest neighbor)
問題によっては抽出されるベクトルが厳密で無くとも良い場合がある。マッチ漏れや順位の上下などをある程度許容することで高速化を目指すアプローチだ。
Faissのインデックス
処理の流れ
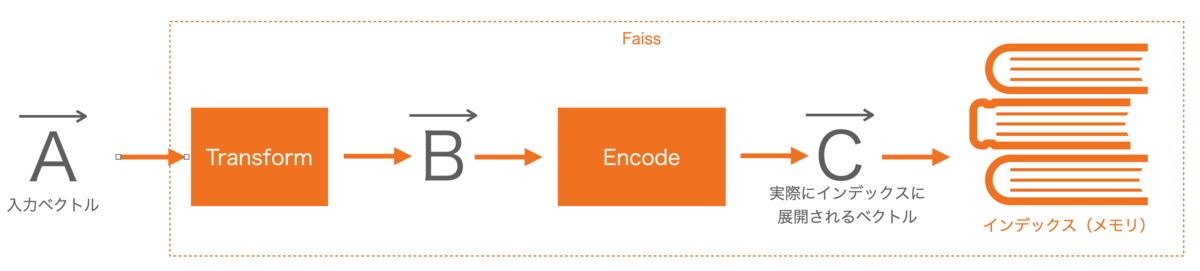
オレンジの部分がそれぞれ柔軟に差し替え可能。
ベクトルAが数万次元であっても(TransformやEncodeのトレードオフを受け入れる事で)ベクトルCを百次元未満にできれば、検索処理やメモリの負荷を大幅に削減できる。
またインデックス部分も単純にメモリ展開するだけだったり、グラフ構造や分散構造を選択できる。(もちろん各構造において色々なトレードオフがある)
Metric
ベクトルの距離計算の定義。主に以下の2つ
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| L2 | 平方ユークリッド距離 | 大小比較するだけならユークリッド距離と同意 |
| InnerProduct あるいは IP | 内積 | ベクトルを正規化しておけば(分母が1になるので)そのままコサイン類似度として使える。 |
基本インデックス
今回のメインコンテンツ。FlatとIVFだけ覚えるだけでも良い。
Flat
与えられたベクトルをメモリ空間にそのまま展開する。
検索は総当り。よって誤差は出ない。 それでもBLASに食わせ易く信じられないほど速い。
メモリーにそのまま展開するためベクトルのメモリー内順序で処理しID管理はしない(できない)。 利用側がベクトルを追加した順番を覚えておかなければならないので取り回しが悪い。
スクリプトなどで一時的なインデックスという使い方に良い。
IVF
総当りに耐えられない数のベクトルを、クラスタリングして小さな nlist 個のインデックスに分けておく。
検索時は、指定したベクトルに近いクラスタ(インデックス)を nprobe 個を対象に検索する。
クラスタリングの常として検索対象に入らなかったクラスタに、本当は近かったベクトルが入っている場合もあり、それらは検索結果から漏れる。
個人的には大体これを使う。
HNSW
ほぼグラフDBと同じ構造。
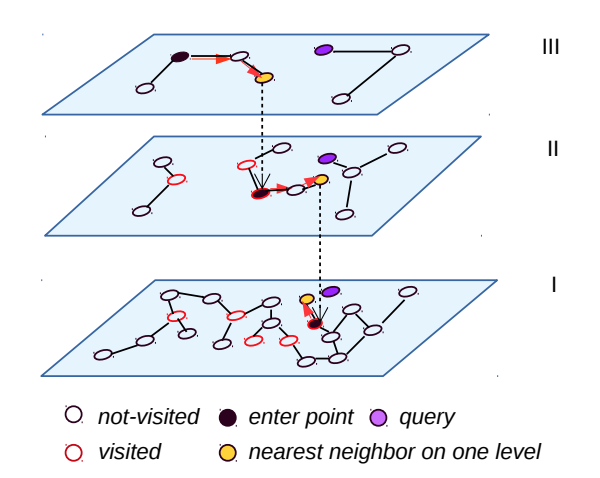
検索時にグラフが追えなくなってしまう為、一度入れたデータの削除ができない。
LSH
閾値の上下の2値化によるハッシュ
あまり精度を必要とせず、大まかな比較になる事が多い。
速度とメモリの制限が非常に厳しい場合の選択肢。
主なTransform
主に次元圧縮え使う事が多い。
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| PCA | 主成分分析 | 意味が薄い次元を省略し次元圧縮 |
| OPQ | ベクトル回転 | 後述のPQの効率化用 |
| RR | ランダム回転 | どう使うのか良くわからない |
| L2norm | 正規化 | ベクトルの大きさを1にする。MetricにInnerProductを指定すればcos類似度となる(実際の値は1-cos類似度)が予め入力ベクトルを正規化しておいた方が良い |
| ITQ | 勉強中 | 後述のLSHと一緒に使う |
| Pad | パディング | どう使うのか良くわからない |
主なEncoding
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| PQ | 直積量子化 | 解りやすい解説 |
| SQ | Scalar quantizer encoding | ちょっと良く分からない。単純なベクトル量子化の事だろうか? |
| RQ | 回帰分析の残差 | 回帰分析に上手く乗るデータ(トレーニングデータで実データを説明できるか?)では残差を量子化すると効率が良い |
| LSH | しきい値以上か未満の2値に量子化 | 高次元ベクトルで次元圧縮をしたくない場合の選択肢 |
PQを使ってれば間違いないがちょっと考える事が多いので後日別途解説する予定。
Prefixes
| Faissでの表記 | 意味 | 備考 |
|---|---|---|
| IDMap | Flatインデックス専用 | メモリー上での実装のみでマップ情報込みでインデックスを永続化できない |
永続化出来ないのでプロセスが起動している間でしか使わないインデックスで採用する事になるが、そういうケースのデータ投入でID管理出来ないような順不同並列投入する事もあまり考えられない為、採用しにくい。
私見だが使い物にならない。
Suffixes
TransformやEncodeを経たデータの距離には誤差がある。 検索結果を返す前に生ベクトルで距離計算をやり直してソートする機能。
生ベクトルを保持する必要があるためメモリー負荷が大きい。
以下の2つがある。
- RFlat
- Refine
サンプルコード
速度が重要な問題なので、サンプルコードも高速な言語であるGOを採用。
Flat L2
最もシンプルなFlatインデックスで平方ユークリッド距離計算。
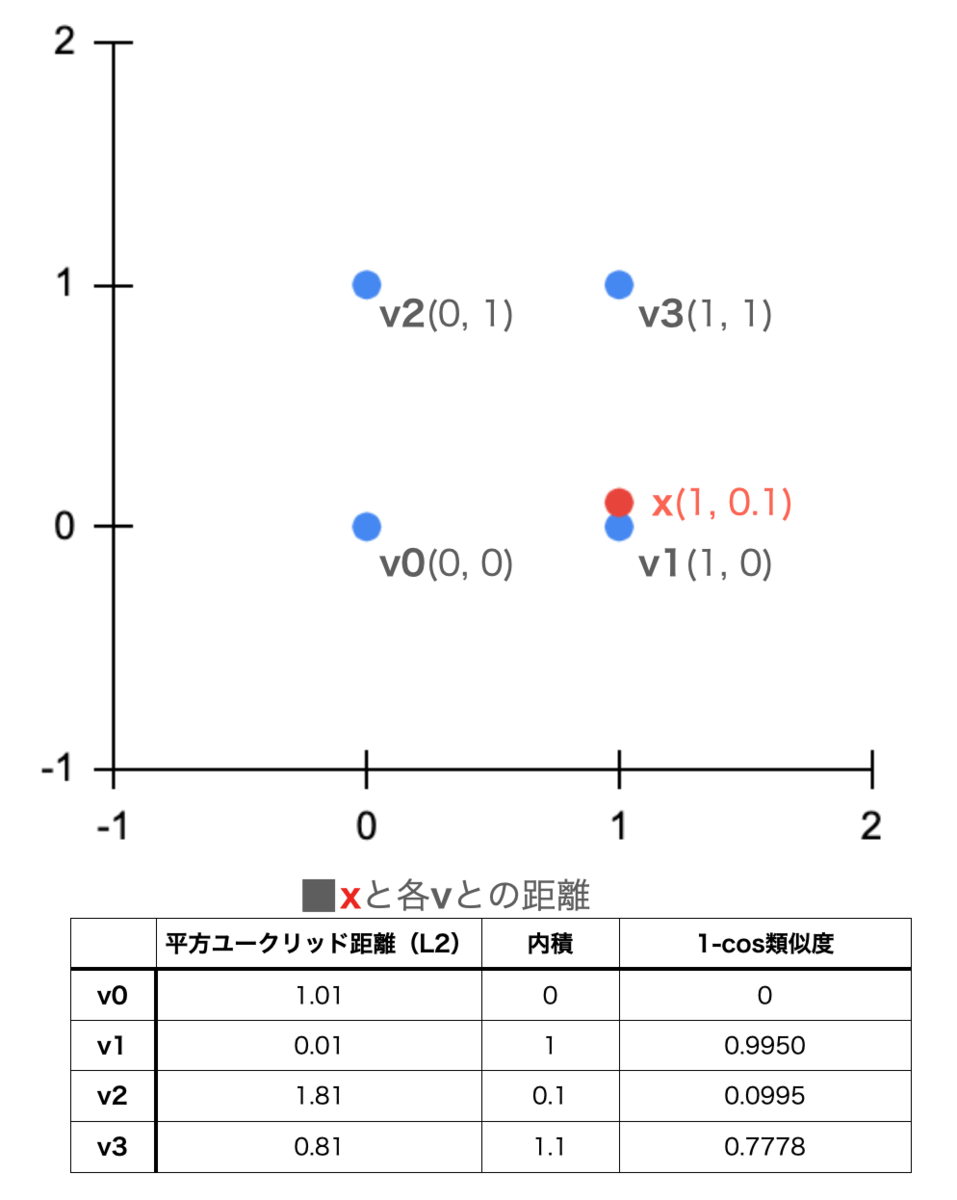
func Sample1() { fmt.Println("*** Sample1 Flat L2") index, _ := faiss.IndexFactory(2, "Flat", faiss.MetricL2) index.Add([]float32{0,0,1,0,0,1,1,1}) fmt.Printf("Ntotal: %v\n", index.Ntotal()) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
2 次元、 Flat 、L2 を指定したインデックスを作成
index, _ := faiss.IndexFactory(2, "Flat", faiss.MetricL2)
2 次元のベクトルを 4 個同時に投入。前述の通りメモリ展開順にラベルが 0, 1, 2, 3 と振られる。
index.Add([]float32{0,0,1,0,0,1,1,1})
実行結果
*** Sample1 Flat L2 Ntotal: 4 Distances: [0.010000001 0.80999994 1.01 1.81], Labels: [1 3 0 2]
Flat IP
メトリックに内積を指定
func Sample2() { fmt.Println("*** Sample2 Flat IP") index, _ := faiss.IndexFactory(2, "Flat", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** Sample2 Flat IP Distances: [1.1 1 0.1 0], Labels: [3 1 2 0]
Transform(L2norm)
正規化ベクトルの内積=1-cos類似度 (1に近い程、近距離と見なされる)
func Sample3() { fmt.Println("*** Sample3 L2norm Flat IP") index, _ := faiss.IndexFactory(2, "L2norm, Flat", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** Sample3 L2norm Flat IP Distances: [0.99503714 0.77395725 0.09950372 0], Labels: [1 3 2 0]
Suffix RFlat
TransformやEncodeとRFlatの組み合わせは上手く動かない。
Transform(L2norm) と RFlatを同時に使うと、RFlatの際にTransformが無視されて、単なる内積が帰ってしまう。
func RFlatDontWorkWithTransform() { fmt.Println("*** RFlatDontWorkWithTransform") index, _ := faiss.IndexFactory(2, "L2norm,Flat,RFlat", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) // RFlat returns simple IP, (Ignoring transform layer) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** RFlatDontWorkWithTransform Distances: [1.1 1 0.1 0], Labels: [3 1 2 0]
Suffix Refine
RFlatの代わりにRefineを使ってインデックスと同じ定義をしてあげれば良い。
func Refine() { fmt.Println("*** Refine") index, _ := faiss.IndexFactory(2, "L2norm,Flat,Refine(L2norm,Flat)", faiss.MetricInnerProduct) index.Add([]float32{0,0,1,0,0,1,1,1}) distances, labels, _ := index.Search([]float32{1, 0.1}, 4) fmt.Printf("Distances: %v, Labels: %v\n", distances, labels) }
実行結果
*** Refine Distances: [0.99503714 0.77395725 0.09950372 0], Labels: [1 3 2 0]
続き
全然書ききれないので、第2回も準備中。サンプルや検証を中心にしようと思っている。
Faissでベクトル検索するDBを開発した
広告プラットフォームcraft に投入
24000次元のSCDVベクトルを数百万件入れてインデクシングしています。
PQ圧縮しているのでメモリー負担は殆ど無く小さなサーバーで運用できています(トレーニングの時だけメモリーが大変)
順次利用範囲を広げていく予定。
faissdb
https://github.com/crumbjp/faissdb

- Faissインデックスを使ったベクトル検索が出来るDB
- ベクトルはユニークキーで管理(Faissの面倒なID管理をしなくて良い)
- 複数のFaiss indexを扱える。(検索対象が用途的に、全体データ、weeklyデータ、monthlyデータ、といった具合に分けたい時には予めfaiss indexを3つ作っておかなきゃならない)
- PRIMARY-SECONDARY の簡易レプリケーション
- クライアントI/FがgRPCなのでクライアントライブラリの開発が容易
依存技術
- golang => C言語を書かずにC言語ライブラリが使えるのが売り
- faiss => ベクトルインデックス検索
- rocksdb => 高性能key-value store
- gRPC => Google製RPC
開発の経緯
faissを使いたいが・・・
C/C++のfacebook製のベクトルANN検索ライブラリ。群を抜いて完成度と柔軟性が高い。
この手のライブラリは作ったインデックスを更新出来ないのが普通だがfaissではインデックスのアルゴリズムを指定する事で、用途に応じたインデックスのメリットと制限をコントロール出来る。
しかしあくまで純粋な検索ライブラリなのでサービスに使うには周辺の処理(メモリー管理やデータ管理など)を自前で書かなきゃならない。
高速実装のトレードオフでインデクスの永続化周りは非常に弱い。
golang
容易にCライブラリを叩く事ができる言語の中では最も高級言語の内の一つ。
goルーチンがメチャクチャ便利なのでデータストアを書くのには向いている。
golang内で取得したメモリーに関してはGCが面倒を見てくれるがCライブラリを叩く場合は帰ってくるデータのメモリーの扱いを気にしなきゃならないので結局ソースは全部読まなきゃ使えない。
駄目なら全部自分で書く覚悟が出来てる時だけgolangを使うのであまり気にならないが・・・
gRPC
protocol-bufferベースの言語非依存RPCライブラリ。
が、クロス言語でコールする場合はちょくちょくバグがあったりして地雷を回避しながらじゃないと使えない。
インターフェース定義ファイル(.proto)から各言語実装をジェネレート出来、使う側は限りなく言語ネイティブで実装できるので負担が少ない。
一緒にベクトルの世界に溺れたい人募集中です
SCDVが出来るまで
SCDVとは?
数多ある文章を評価する手法の中で速くて安くて旨いと噂されているもの
趣旨
実験的な実装やその結果は色々手に入るが実際にある程度の規模のサービスに使うとなると、どんな苦労があるのかを紹介しようと思う。 コードレベルの詳細な解説は他所に譲る。
大本
解説サイト
丁寧に解説してくれているサイトが沢山あるので詳しくはそちらを見て欲しい。
文書ベクトルをお手軽に高い精度で作れるSCDVって実際どうなのか日本語コーパスで実験した(EMNLP2017) - Qiita
文章の埋め込みモデル: Sparse Composite Document Vectors を読んで実装してみた - nykergoto’s blog
手順(詳しくは上記のリンクを参照)
1.日本語コーパスを作る 2.Word2VecとIDFを算出 3.WrodVectorをGMMでトピッククラスターに分類 4.WordTopickVectorを得る 5.実際の記事にWordTopicVectorを適用し、文章ベクトルを得る。
0.ベクトル精度の評価方法
最終的にユーザ行動で判断する。
関連性の高いものを出すべき所で、関連性が高い(とシステムが判断した)ものを出した場合、ユーザーのリアクションに現れる。その数字を見て判断する。
面白いのは高関連度帯と低関連度帯で全く逆の成績(ユーザの反応)を得る場合があった。
大まかに見ると(高関連度帯)非常に上手く行っているモデルでも細かく見ていくと齟齬が多いということで サービスとしては文章ベクトルはあらゆる箇所で応用して使って行きたいのでなるべく細かいところまで精度を求めたい。
1.日本語コーパスをつくる
一般的なWebメディアの記事は、表記の揺れや偏り、口語調、中には非論理的な記事も含まれる場合があるので それを嫌って試しに日本語WikiのみでSCDVまで作ってみたが全く使い物にならなかった。
表記ゆれや、WEB特有の無効なワードに付き合って行く必要がある。
無効ワード
WEBでは文章の意味に関与しないワードが多数あり、これはコーパスを作る段階でも、実際文章を評価する段階でも除外しなければならない。 またascii や半角カナなども全角大文字正規化して扱っている。
ページ構造にまつわるもの
- タイトル、トピック、コンテンツ
- 次ページ、前ページ、NEXT
- トップページ、TOP
- NEW、新着
WEBメディア語
- オススメ、おススメ
- 大人気、話題、必見
- あなた(に、へ)
EC語
- サイズ、幅、奥行き、高さ、重量、KG
- 価格、通常価格、特別価格、本体価格、販売価格
- YAHOO、楽天市場、AMAZON
イベント系?
- オリジナル、プレゼント、キャンペーン、期間中
- 開催日時、TEL
お腹いっぱいすぎる。。。
まだまだ数百あるが根本的に果がない。 先に述べた、高関連度帯ではある程度無視できるが、細かい精度を求めると記事元メディアや記者単位にの適度な頻出度になる単語も多くIDFでは影響を取り切れない。
地道に確定データを作って行けばDeepLearnで検出できるとは思う。
データ量
日本語Wikiと、我々の広告サービスでタグが埋まっているサイトの記事データからコーパスを作るが
wikiが200万記事6GB、サービス側のデータが260万記事14GB程度となる。
サービス用tokenizer
最終的にサービスで使うので、サービス用のtokenizerで処理する。
mecab-ipadic-neologd は必須アイテム。
nodejsからmecabを使う場合、mecabコマンドを叩いて(fork)いてるライブラリばかりで使い物にならないので ネイティブバインディングを自作している。 mecab-gyp - npm
- 正規化
- 名詞、動詞のみを抽出。(動詞は含めた方が若干良さそう)
- 非自立、数、形容動詞語幹、副詞可能などと、上記無効ワードを除外
- さらに特殊条件(ひらがな1文字など)で色々除外
- これでも抜けてくる除外したいワードを目検で取る。(なる、ある、ほか、等)
最終的に、10億ワード(900万ユニーク)10GBのコーパスが出来た。
他にも色々込み入ったロジックを実装している事もあり、100並列で1〜2時間かかる。
2.Word2VecとIDFを算出
隣のドキュメントと混ざらないようにwindowサイズ分のパディングを入れておく。
(あまりコレやっている人が居なそうなのはなぜだろう・・・)
gensimで一発。96コアのサーバーで130並列位かけると100%使ってくれる。
これも数時間かかる。
頻出度により約64万単語になった。
3.WrodVectorをGMMでトピッククラスターに分類
sklearnのGaussianMixture で丸一日!!
とにかく時間がかかる。並列化も望めないので悩みのタネ。
しかしここで最終的な文章ベクトルの精度の全てが決まるので何度も実行する事になる。
更にここで視覚的に精度を検証する術がない。
つまり最後まで行ってからココに戻ってくる。。つらい・・・
t-SENによる視覚化




評価不能・・・
Word2Vecってワード数が少なくてもこうなるので評価の仕方が本当にわからない。
トピックベクトルまで行っちゃうと今度は色分けする意味が無くなるし困ったものだ。。
4.WordTopickVectorを得る
64万単語、200次元(word-vector)、400クラスターともなると使用メモリーが数十GBを超える。 処理途中も合わせると更に必要になる。単にnumpyで素朴に
(words * clusterWeights) * idf
って訳には行かない。
単語はファイルに落としておいてストリーム処理する。そこまでやるなら並列化は簡単。
単にベクトル演算なので詳細は略。
次元の謎
word2vecは200 〜 300次元、clusterは 50、60 〜 という話だが、この辺はどうにも体感値が違うようだ。
word2vecでは、200次元と300次元の違いが僅かで、cluster は 大きければ大きい程よさそう。 扱ってるコンテンツの幅が広いのが原因だろうか。。
word2vecを400次元以上にするとまた変わるのかもしれないが、試すのはいつになる事やら・・・
5.実際の記事にWordTopicVectorを適用し、文章ベクトルを得る。
ランタイムで記事データを分類するとなると得たベクトルはその最大精度では使えない。 8万次元ものベクトルをユーザアクセスの度に扱うのは重すぎるからだ。
wordTopicVector 自体を1% ~ 3% 程度にスパース化しておく。これで実効1000次元。
これを文章に適用していくと、文章ベクトルが数万次元になってしまうので、それもまた1%程度にスパース化(&正規化)する。
これでドキュメント同士の比較は数百回の掛け算処理になる。
あとドキュメント中に同じ単語が複数回現れる時の扱いでかなり精度が変わるのでここは工夫が必要。
セイコーの腕時計の記事とシチズンの腕時計の記事では、各々セイコーとシチズンを連呼する(しかもIDFも大きい)。上手く扱わないと文章ベクトル自体がセイコーとシチズンになり、記事の共通部である腕時計との距離がどんどん離れて行ってしまう。
Webの記事は表現が節操がないといつも思う
学問的にはともかくサービスとしてはオーダーメイドチューンすべき所だ。
データストア
ここまでデータを圧縮してもランタイムで使うならば毎回DBから引く訳にも行かずメモリーに貯める訳にも行かない。
そもそもメモリーに全ては入らず、一部であってもランタイム用のワーカープロセス1つずつに持つのは非効率(サーバーメモリが潰れる)
じゃあredisに入れる?

即死!!
wordTopicVector も文章ベクトルも置き場に困る。 100GBクラスで即応性があり格安で使えるデータストアが必要!!!
これが解決しないなら更に次元を落とすしかない・・・
成果
実際のサービスでの配信での成績の一例
ユーザーは今見ている記事と関係ある記事ほどクリックする確率が高いと仮定すると文章ベクトルの類似度とクリック率に一定の関係が現れるはずだ。 ElasticSearchのmltスコアによる分析と比較して検証する。
よくできました 💮

ElasticSearchと同程度のクリック数を切り取りながらもCTRの高い層を抽出出来ている。
これはSCDVによる類似度分析の結果をユーザ行動が支持したといえる。
細かい部分も大丈夫そう💮

ElasticSearchのmlt scoreが高いゾーンでもSCDVの分解能が機能しているともいえる。
もっとがんばろう💢

ElasticSearch よりも大きくクリックを削っているにも関わらずCTRも低くなってしまっており完敗。
色々見ていくと、ある特定のジャンルを苦手にしているようにも見え、GMMの段階でおかしくしちゃっているトピックがあるんじゃないかと考えている。
まとめ
今回、SCDVによる文章評価を曲がりなりにも本番投入まで持っていき、ある程度の有用性や可能性を見出すことが出来た。
ただ、精度面、性能面での大きな課題もあり、しかもバーターでバランスを取るとなると安定させるためには未だ相当の労力が必要そうだ。
特に重要なポイント
- Tokenizer 全ての入り口にして、精度に最大寄与する部分。特に細かい部分の精度を求めた時ほどココの撃ち漏らしの影響が大きくなる。
- 次元 WordVector と ClassSize のバランス。最終的な性能まで含めて考慮する。
- GMM 時間がかかる上にWordTopicVectorの精度に大きく関わる。単体で評価しにくいのも厄介。
この辺、検討している人がいたら参考にして頂けたら。また情報交換などぜひぜひ。
AWSでもsysctlやらなきゃならんのか・・・
問題
構成
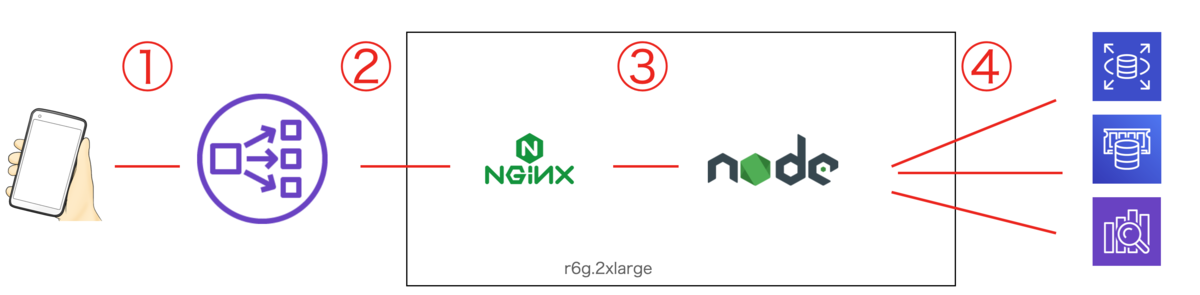
突発的に、1台のサーバーで5秒間だけ、502 Bad Gateway が数百〜数千出て困った。(②の部分)
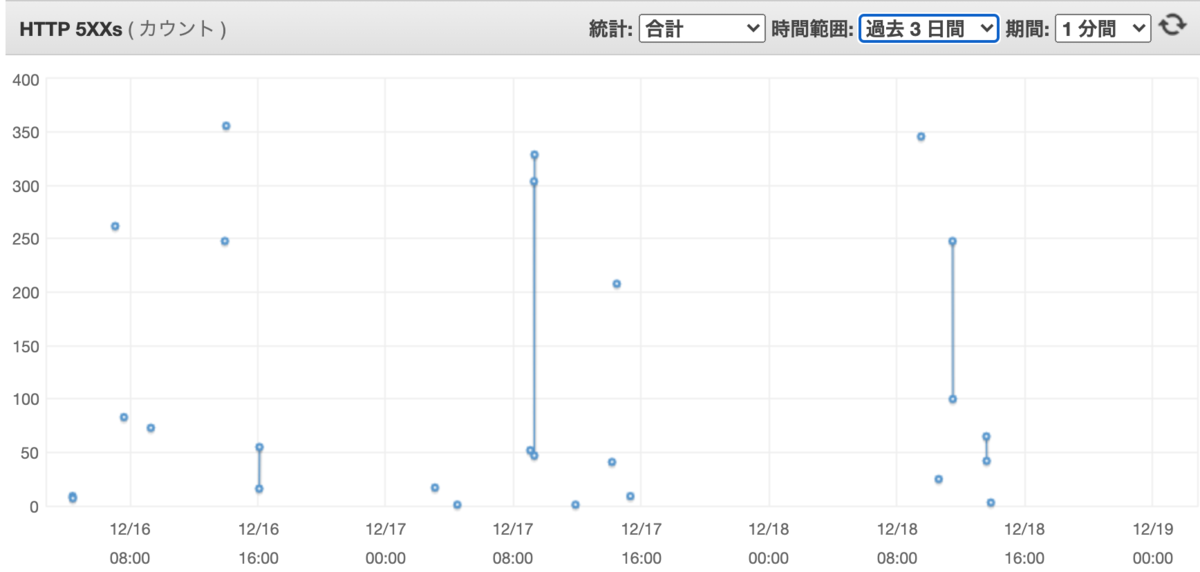
- nginx.conf
proxy_connect_timeout 5;
5秒はnginx設定によるモノなのだろうが、なんで一瞬だけ出るのか全然解らなかった。
nginxのerror.log にはこう出てて、これってproxy_passの設定ミスってる時の奴だよな。。と。。(③の部分)
- /var/log/nginx/error.log
upstream prematurely closed connection while reading response header from upstream, client: 172.XX.XX.XX, server: _, request: "GET / HTTP/1.1", upstream: ...
一瞬、nginx -> node 間の unix socket の接続が詰まってパイプ詰まり問題でクライアント側まで詰まったのだろう。
パイプ詰まりにはバッファリングが常套手段なんだが、
しかしそもそもCPUもメモリーも問題無いのに、なんで詰まるんだ??
色々調べる内に全然違う部分の問題を発見する
$ netstat -s | grep -e 'pruned' -e 'collapsed'
1919109 packets pruned from receive queue because of socket buffer overrun
15131248 packets collapsed in receive queue due to low socket buffer
なんか多くないか?これ多少は出るのは良いんだが秒単位でガンガン増えてくのはおかしい。
EC2は色々なサイズのサーバーをスグに作れるし、気軽にサイズを変えられるし、そうするとCPU,メモリーどころかネットワーク帯域まで丸ごと変わるので細かいチューンをする気は無かった。
だけど、これ明らかにソケットバッファが足りてない!
これを踏まえて仮説を立てる
④の通信が滞って最終的には詰まり、瞬間的に③が何かしらの一時的リソース不足(※1)で受け付けられなくなり、②、①の502に至る。 だから④の通信をチューンすれば解決するのでは?
- ※1これも少なくとも5秒以内に解消する一瞬の問題なので捕まえられずにいる。計算上nfileやmaxconnでは無い事は解っている。heapsizeとかはあり得る。socketの先のカーネルで秒単位で起きる事といえば、ネットワークの輻輳が何かしらのロックを引き起こしている。とか。。しかしこれは追う気が起きない。多分追っても問題解消しねーし。
検証
えー今の時代にこんな細かい所調整すんのかよ・・・
net.core.somaxconn = 30000 net.core.netdev_max_backlog = 30000 net.ipv4.tcp_tw_reuse = 1
今までのsysctlの設定まさに動けば良い!的wこれが今風だと思っていた・・・
他はデフォを使っていて、特に関係ありそうな所はこの辺り。
net.core.rmem_default = 212992 net.core.rmem_max = 212992 net.core.wmem_default = 212992 net.core.wmem_max = 212992 net.ipv4.tcp_rmem = 4096 131072 6291456 net.ipv4.tcp_wmem = 4096 16384 4194304
ん?TCPのバッファってcore超えてて良いんだっけ?
調べたらMAX側が削られるだけらしい。
それでも200KBって少ない感覚だが昔の感覚と今の光配線やスイッチ性能だとレイテンシが段違いなんだろうな。
まずはネットワークバンドを確認
r6g.2xlargeは最大10Gbps だがPear To Pear だとどうなのよ?
# iperf Command 'iperf' not found, but can be installed with: apt install iperf
あ、、最近こんなことしないから入ってもいねーや
# apt install iperf
で、RDSやelasticCacheへは直接計測出来ないから、隣の別AZサーバー(placement groupではない)へ向けて計測
10K 位がメインの通信サイズ
ServerA
# iperf -s -w 1M
ServerB
# iperf -w 10K -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 20.0 KByte (WARNING: requested 10.0 KByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.1 sec 37.4 MBytes 31.1 Mbits/sec
案外細っ!、いやAZ超えればこんなもんか。やっぱ実測は大事。 1window 辺り3.2ms
1M 位が最大レベルの通信サイズ
ServerB
# iperf -w 1M -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 2.00 MByte (WARNING: requested 1.00 MByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 766 MBytes 643 Mbits/sec
1window辺り15ms
Round Trip Time (RTT)
# ip tcp_metrics : XXX.XXX.XXX.XXX age 2306.848sec cwnd 10 rtt 14817us rttvar 14478us source XXX.XXX.XXX.XXX :
redisへの計測値 elasticCacheと隣のEC2の経路は違うから、まあ参考値でしか無いが、redisとはかなり大きめのデータをやり取りしているようだ。
アプリとしては小さなキーを扱っているのだが、multiで纏めて送っているケースも多いのでまあ納得。
そしてこれは計算しなくても感覚的にやばい。
計算
TCPは再送があるので、向うにデータが到着して届いたよ。の返事が来るまで送信データを捨てられない。 elasticCacheはバンドの実測が出来ないので仮に1M windowの時のbpsを使う。
643 Mbits/sec * 14.817ms = 9527331 bits = 1190916 bytes
約1MBのバッファが必要なようだ。色々仮置数字がある計算なので、僕はこういう時は3倍にする。(感覚以外の裏付け無し)
設定を変えてもう一回計測
# sysctl -w net.core.rmem_max=3145728 # sysctl -w net.core.wmem_max=3145728 # iperf -w 1M -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 2.00 MByte (WARNING: requested 1.00 MByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 3.72 GBytes 3.19 Gbits/sec
おお!全然違うじゃねーか!! ちなみに10Kの方は 31.1 => 201 Mbits/sec
こうなると50MB近くバッファが必要になるな。でもこういう時には大体効かないもんだ。しかしやってみる
# sysctl -w net.core.rmem_max=52428800 # sysctl -w net.core.wmem_max=52428800 # iperf -w 1M -c ServerA ------------------------------------------------------------ Client connecting to ServerA, TCP port 5001 TCP window size: 2.00 MByte (WARNING: requested 1.00 MByte) ------------------------------------------------------------ : [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 3.78 GBytes 3.24 Gbits/sec
うん。3Mでいい。
設定
そもそも
EC2はサーバサイズをフレキシブルに変えられるのも大きなメリットで、一緒に変わるネットワークバンドに合わせたチューンに依存したシステムは事故の元。本当は、ソケットバッファサイズは弄りたくない。
問題点の最終検証も兼ねてソケットバッファ以外の悪あがきをしてみる。
fin_timeout やコネクション数を弄って、枯渇リスクを回避できるか?
net.ipv4.tcp_fin_timeout = 5 net.ipv4.tcp_max_syn_backlog = 4096 net.core.netdev_max_backlog = 60000 net.core.somaxconn = 60000 net.ipv4.tcp_tw_reuse = 1
この辺の悪あがきも効かず。
net.ipv4.conf.default.accept_source_route = 0 net.ipv4.tcp_rfc1337 = 1
socket buffer をチューン
net.core.rmem_max=3145728 net.core.wmem_max=3145728
効いた!!
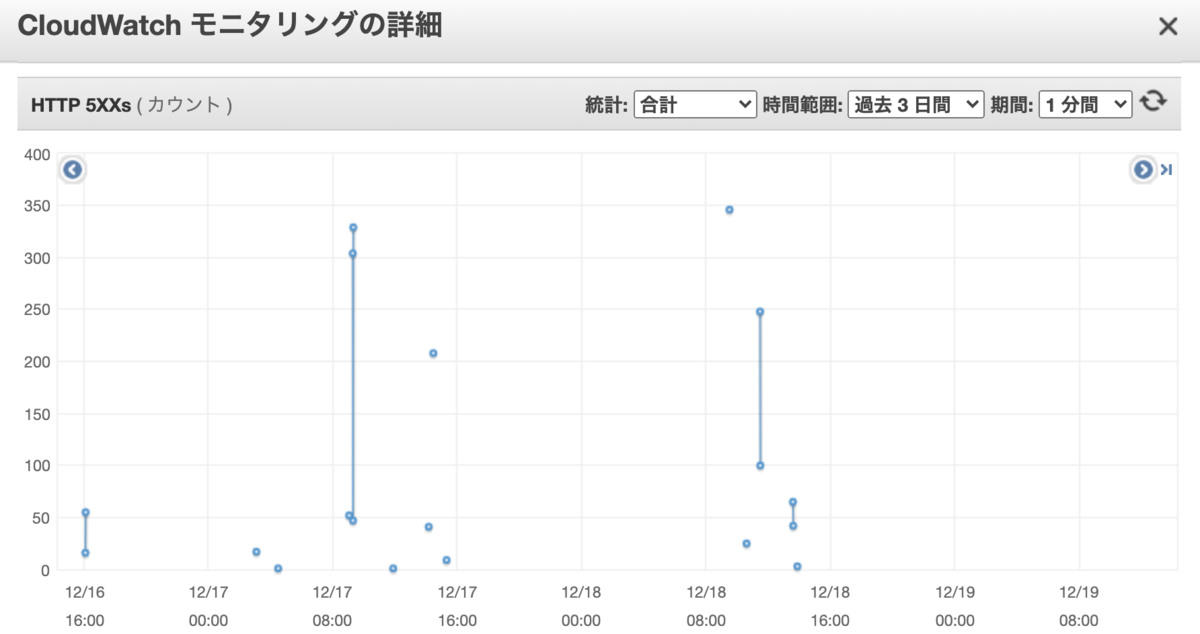
1日平和だった。ビックリするくらい劇的に改善!!
やっぱAWSパワーで解決はだめだ。順を追って丁寧に解決していくインフラ的な作業はまだまだ残るのだな・・・
おっさんの悩み
インフラ知識は本来コンピューターの全ての基本なのだが、これだけ発達した技術の中では全部身につけるのは非効率だと思う。 若い技術者は即効性のあるサービスに直結する新技術を学んで、すぐに戦力として活躍して欲しいし、殆どの人はそうしている。
それが効率的だ。
しかしそうすると誰もインフラが解らないチームが出来上がる。 一つ一つ細かく紐解いていく事が出来ない(思いも寄らない)から金で解決する事になる。でもこれって技術力の敗北だよね?
技術者全体、業界全体として力が失われていく圧力に他ならない。(今のSI界隈を見てると強く感じる)
また民芸の後継者問題よろしく、インフラ解る人が劇的に減ってきて、歯止めが掛かる気配がない。 やっぱり若い技術者もしっかりインフラをやらせた方が良いんだろうか?ぐるぐる。。。
Graviton2のアクセラレータの効果
前回の続き 2020-06-18から1日間の記事一覧 - 中年engineerの独り言 - crumbjp
2xlarge以上は圧縮アクセラレータが付くらしい
P24.
• 1Tbit/s of compression accelerators • 2xlarge and larger instances will have a compression device • DPDK and Linux kernel drivers will be available ahead of GA • Data compression at up to 15GB/s and decompression at up to 11GB/s
本番をサーバの負荷
・c6g.xlarge x 11 から c6g.2xlarge x 10 に変更

微妙にCPU数が減っているにも関わらず負荷は低減した。 プロセスの構成は、nginx => nodejs (express) 。
・nginx のCPU負荷が劇的に低減 => gzip on; の部分が効いたと思われる。
・nodejsの負荷も下がった。socketIOのペイロード圧縮部分が効いていると思われる。
というわけで、c6g.xlarge x2 よりは c6g.2xlarge x1 の方がお得。
AWS Graviton、Graviton2 インスタンス別性能
前回の続報 crumbjp.hateblo.jp
ARM64バイナリ用のインスタンスタイプ別の状況
網羅的にやる気は無く、自分に必要な範囲で調べただけ。
| instance type | CPU能力 | SPOT | AZ |
|---|---|---|---|
| a1系 | m6gの半額程度 | 潤沢 | 1a,1d |
| m6g系 | c6gと遜色なし | 買える | 1a, 1c |
| c6g系 | 高 | 枯渇 | 1a, 1c |
| r6g | c6gと同程度? | 枯渇 | 1a, 1c |
見ての通り a1系(Graviton)は性能が低いが スポット在庫が安定しているのでコストメリットが高い。 しかしAZの取り回しが面倒だ。
スポットの価格も1dの方が格段に安い

フットワークの軽いインフラ屋さんが居ないと使いにくいが利益はある。
CPU実測

水:m6g.xlarge、橙:a1.xlarge、他:c6g.xlarge
間違いなくm6gはお得。
AWS Graviton2
最大40%のコストカット!
魅力的だが、ARMアーキテクチャのプロセッサなのでバイナリから違うのが面倒くさい。 サラのOSディストリビューションから作り直しなので現行のサービスでテストするにはかなりの障壁。 人柱記事が出てくるまで時間がかかりそうだ。
僕は人柱は滅多にやらない主義なのだけど 価格の魅力に負けて食いついた。
ubuntu18.04 ARM64の問題
ubuntu-defaults-jaが提供されてない!
でも、幸いな事にこれ以外に大きい問題はなかった。 コレくらいなら、by hand でなんとかできそう。
オンデマンドの価格
c5系の80%の値付けになっている。 Amazonは40%のコスト削減が出来ると大口を叩いているがCPUが相当早いということかな?
| タイプ | CPUs | メモリー | 価格/h |
|---|---|---|---|
| c5.xlarge | 4 | 8GiB | $0.1712 |
| c6g.xlarge | 4 | 8GiB | $0.214 |
プロダクションに適用
アドネットプラットフォームの処理は、CPU処理が多く、DB処理が少ない(殆どをキャッシュで処理するため)。 また少しでも早くレスポンスを返したい為、C系のサーバーを使っている。 この環境に1台混ぜてみる。(STGはインスタンスタイプを小さいモノにしてケチって居たためよく解らなかった。。)
CPU使用率

- 一番下の水色 c6g.xlarge
- 中央の塊が c5.xlarge
- 上の2つが m3.xlarge
m3はスポットインスタンス(c5が枯渇して買えない為・・・)。ECUが全然違うので、同じxlargeでも全然違いますな。 そして肝心のc6gは、顕著に早いって訳ではないが、c5相当のECU換算20以上はありそうだ。 なので、Amazonの40%は吹きすぎ(CPUだけの話じゃないのかな?)だが、リーズナブルである事は間違いない。